Dans un simulateur, un agent pourvu de coordonnées uniques ne peut pas se trouver sur deux types de terrain en même temps (bâtiment et champs) ; à la question « quel élément se trouve à cette coordonnée » on ne veut avoir qu'une seule réponse possible.
Lors de la création du shapefile, même si les polygones existent et sont bien placés et définis, leur superposition pose donc problème.
Dans l'exemple ci dessous, le logiciel ne fait pas de distinction entre les deux figures. Le point A appartient donc aussi bien au rectangle rouge qu'au rectangle bleu.
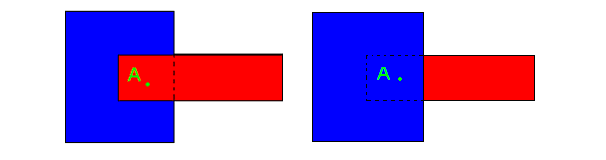
Si l'on prend l'exemple d'un bâtiment dans un terrain, lors de la numérisation on se contente de créer deux rectangles superposés (le tracé de Google Earth ne permet pas de créer des polygones avec des « trous »). Le polygone terrain existe donc « sous » le polygone bâtiment (dans le cas où il ne masque pas celui ci).
Ce problème peut être résolu visuellement en utilisant des priorités de couches et de degré de transparence, mais elle n'est pas très satisfaisante pour effectuer des traitements et des requêtes spatiales.
Nous allons donc effectuer un traitement sur le shapefile pour faire en sorte qu'un point donné n'appartienne qu'à un seul polygone.
Découpage d'une couche par une autre
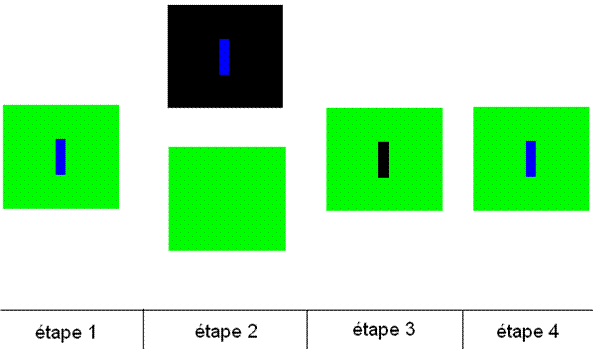
Pour effectuer ce traitement sur un cas précis, il est possible de découper chaque zone en fonction des couches qui lui sont supérieures.
Nb: noir = vide
On découpe à l'aide d'une fonction d'intersection une couche « champs » pour créer des trous dans les polygones là où se trouvent des bâtiments
- étape 1 : on différencie les couches en faisant des extractions en fonction des attributs (on peut le faire en utilisant une jointure pour ne conserver que les éléments d'un certain type)
- étape 2 : On utilise une fonction « geoprocessing » de différence pour soustraire la couche bâtiment à la couche terrain. On obtient ainsi un terrain qui ne sera pas défini là où se trouvent les bâtiments
- étape 3 : Il faut ensuite réunir les couches après modifications en utilisant une fonction d'union.
- étape 4 : Le shapefile résultant ressemble exactement à celui de départ, mais il ne contient plus qu'une seule épaisseur.
Cependant cette solution n'est pas adaptée lorsque l'on travaille sur un fichier shapefile contenant plus de trois ou quatre couches. Même si les traitements à effectuer sont relativement simples, il faut faire un nombre important d'opérations pour soustraire toutes les couches puis les réunir.
Pour simplifier ce traitement, il est possible d'utiliser des fonctions de PostGis qui permettent de réaliser rapidement des opérations complexes.
Utilisation de PostGIS
Pour commencer, il faut importer votre fichier shapefile en tant que table de données dans PostGIS. Pour créer cette table nous allons utiliser une requête SQL.
- 1. Dans la console, entrez :
- shp2pgsql carte.shp carte_init > creer_table_carte.sql
- 2. Il faut ensuite lancer l'interpréteur de requête SQL et vous connecter à la base de donnée. Pour lancer l'interpréteur, il suffit de taper : psql « nom_de_la_base »
- Vous pouvez ensuite accéder aux commandes disponibles en tapant « \? » (NB: \d liste des tables dans le serveurs, \d nom_table, description de la table nom_table)
- Pour entrer des commandes concernant le shell normal, il faut précéder la commande par « \! »
- 3. Pour lancer la requête SQL que vous avez créé précédemment, il faut entrez la commande
- « \i » « le chemin du fichier contenant la requête sql »
- \i creer_table_carte.sql
Pour pouvoir produire un code facilement adaptable quel que soit le nombre de couches et leur ordre, nous allons nous imposer une règle:
Dans le cas d'une superposition de polygones, on découpe les éléments de l'intersection des deux polygones concernés, et on rajoute la partie « découpée » du polygone qui contient la plus petite aire.
Ces conventions permettent de conserver la logique de répartition et de valoriser les plus petites zones. De manière générale les petits éléments recouvrent les plus grands. On peut alors afficher les couches par ordre logique.
⇨ Le polygone de fond qui est le plus grand sera écrasé par les polygones terrains, à leur tour écrasés par les polygones arbres.
Ainsi, il n'est plus nécessaire de créer des dizaines de couches intermédiaires pour faire attention aux priorités d'affichage. On peut donc traiter rapidement des fichiers relativement complexes:
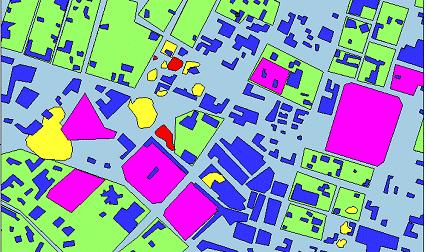
Dans l'exemple suivant, on retrouve de nombreux cas de superposition, mais les zones en conflit sont attribuées aux polygones ayant la plus petite surface. On conserve ainsi une plus grande précision, on ignore juste les parties recouvertes des polygones « conteneurs ».
Cette façon de procéder permet de donner une priorité plus haute aux éléments contenus en découpant les éléments qui les englobent.
4. Une fois que vous avez intégré votre fichier shapefile dans une base de données PostgreSQL, vous pouvez utiliser la requête SQL suivante ( soit en l'enregistrant dans un fichier avec comme extension .sql et en le lançant dans l'invite de commande en console de Psql, soit en passant par l'interface graphique de PGAdmin ( un gestionnaire de base de données PostgreSQL). :
Les codes suivants sont commentés pour vous aider à comprendre la technique mise en place, il suffit de l'adapter selon votre fichier. Il faudra modifier le nom de « kedougou » par la table qui contient votre shapefile et éventuellement modifier les attributs concernés.
DROP TABLE IF EXISTS table_resultante ; --on supprime la table dans le cas ou elle existe déjà depuis un test précédent
CREATE OR REPLACE VIEW kedougou_auto_join AS SELECT
kedougou.gid as gid,
kedougou."name" as "name",
kedougou.descriptio as "descriptio",
GeomUnion(kedougou.the_geom) AS full_geom,
GeomUnion(kedougou_bis.the_geom) AS shared_geom
FROM kedougou ,kedougou AS kedougou_bis-- on récupère tous les éléments de la table kedougou dans deux --collections pour pouvoir les comparer.
WHERE
--on vérifie la validité des polygones testésST_IsValid(kedougou.the_geom) AND ST_IsValid(kedougou_bis.the_geom)
--on filtre pour conserver les polygones en intersectionAND intersects(kedougou.the_geom,kedougou_bis.the_geom)
--on élimine les polygones en intersection avec eux mêmeAND kedougou.gid <> kedougou_bis.gid
--pour une intersection de 2 polygones, on n'en garde qu'un ( le plus petit)AND Area2d(kedougou_bis.the_geom) < Area2d(kedougou.the_geom)
--puisque l'on fait des "unions”, il faut effectuer un regroupement sur les autres attributsGROUP BY kedougou.gid,kedougou."name" , kedougou.descriptio ;
/*On va créer une table qui va contenir le résultat final en soustrayant à la carte complète les polygones de la table précédentes (on supprime ainsi les zones en conflits).
Une fois la soustraction faite, il suffit de rajouter les polygones manquants à savoir ceux qui étaient en conflit mais avec une taille inférieur aux polygones soustraits. En procédant ainsi, on est donc sûr de conserver la surface initiale mais en supprimant zones en plusieurs épaisseurs
*/
CREATE TABLE table_resultante AS SELECT
gid,
"name",
descriptio,/*
On soustrait les "petits polygones" en intersections à la couche contenant tous les polygones; on supprime ainsi les parties en conflits
*/
multi(difference(full_geom,shared_geom)) as the_geom,
area2d(full_geom) as area
FROM kedougou_auto_join
WHERE ST_IsValid(full_geom) AND ST_IsValid(shared_geom)/*
On doit ensuite rajouter les "petits polygones" que l'on vient de soustraire pour « boucher » les trous crées.
*/
UNION
SELECT
gid,
"name",
descriptio,
the_geom,
Area2d(the_geom)
FROM kedougou
– c'est à dire ceux dont le gid n'est plus présent
WHERE gid NOT IN (SELECT gid FROM kedougou_auto_join);/*
On redéfinit ensuite une clé primaire. Même si cette étape n'est pas nécessaire pour créer la table, elle est nécessaire pour que QGIS puisse l'interpréter (il lui faut un index).
*/
ALTER TABLE table_resultante ADD CONSTRAINT pk_table_resultante PRIMARY KEY (gid);
5. Aller ensuite dans QGIS,
⇨ choisir l’icone ‘ajouter une couche PostGis’,
⇨ choisir la table table_resultante (dans ce cas),
⇨ vérifier le bon détourage des polygones,
⇨ sauvegarder la nouvelle couche au format .shp.
Mémo 9 - Auteur Q.Baduel, MAJ 19.12.12 par jlefur
![]() retour aux mémos
retour aux mémos
![]() retour au modèle
retour au modèle
![]() retour à la page d'accueil
retour à la page d'accueil